


The AddTrust External CA Root expiry on the 30/5/2020 has caused some issues for older clients, while the fix on Linux based systems is quite widely documented, for Windows its a bit less clear.
The quickest fix is to open the certificate store (mmc > add remove snap in > certificates > local computer), and set each AddTrust Certificate with the 30/5/2020 expiry to disabled (right click the cert, properties, and set to disabled), then reboot the server. In my experience the certificate under ‘Trusted Root Certification Authorities’ did the trick.
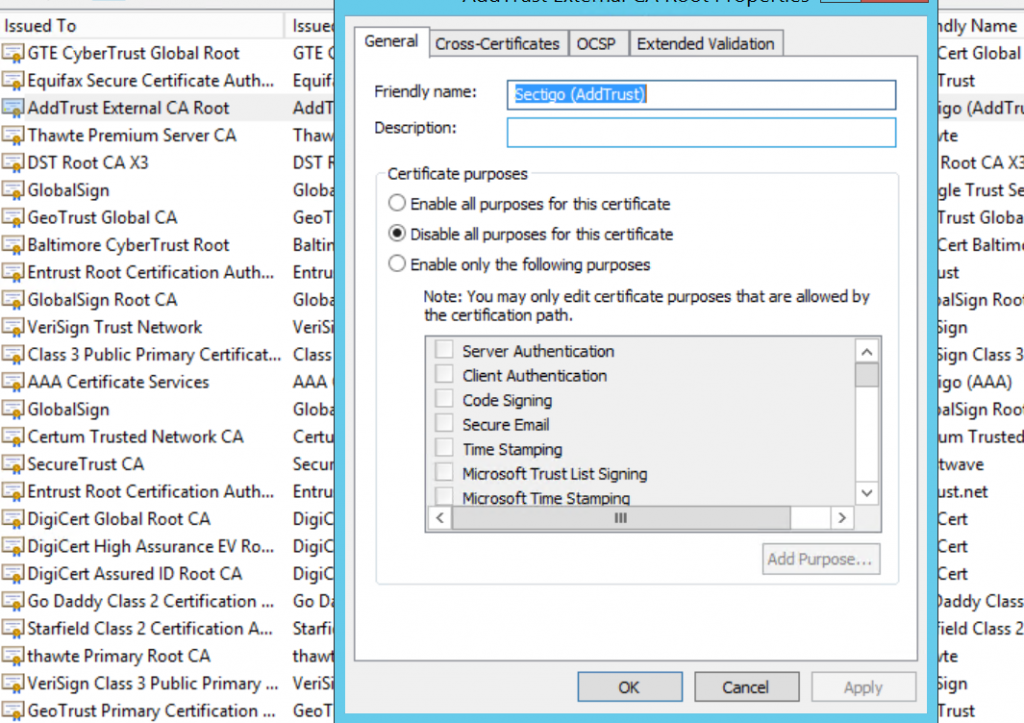
Then the chain should verify on a checker such as https://whatsmychaincert.com/
Just a quick warning for anyone updating their MEM plugin to v1.1.1, we experienced an issue where our ESX hosts started purple screening a few days after they were updated. There is nothing about this in the release notes, nor do Dell seem to be any the wiser, however VMware have a case open with engineering around it.
I can’t seem to find anyone else reporting this online, but seems we are not the only ones according to VMware, so be beware until they release a workaround/fix.
The party line seems to be downgrade to v1.1.0 and forget about the array firmware v6 until this is sorted. Lovely crash output below….now to run through all our hosts and downgrade…..

Having just received my shiny new iPhone 4S 64GB, I was expecting similar battery life to my existing iPhone 4. However after a few days usage it became apparent that I was lucky to get to 5pm with 30% left….hardly ideal.
I disabled location services, and iCloud syncing, and was left with just one activesync mail account….but no, same problem by 5pm I was running low on juice.
Arms up in despair, I tried DFU restore, and restored a backup after that….BINGO, we have decent battery life again 🙂 Full instructions below:
iPhone DFU Mode Explained: How to Use & Enter DFU Mode on iPhone
Let me know if it helps your battery situation.
Over the last few months we have been busy working on a new concept to offer pay as you go credit reports to small and medium sized businesses. No contracts, no tie ins, just information from one of the UK’s largest credit reference agencies provided instantly online with easy to read reports and a recommended monthly credit limit.
It’s all about small business, who don’t always have the resources or knowledge or decipher the existing reports available, or don’t want to prepay for multiple reports at once to get the price down.
Have a look at http://www.checkmyclient.com !
After attempting to upgrade a few cPanel servers this morning to resolve a phpMyAdmin issue, 50% updated fine, the other half had the error:
The update server is currently updating its files.
Seems one of the update servers is having an issue, if you open the file below and remove the IP – 94.75.231.77
/root/.HttpRequest/httpupdate.cpanel.net
Then run the update again 🙂
Since upgrading the Vigor 2820 in the office to the latest 3.3.4 firmware we have had issues with some Snom VOIP phones registering to our * PBX. The phones showed UDP packet errors, but the packets weren’t making it to the PBX.
Unfortunately we had upgraded * around the same time, so most efforts were focused there rather than on the router. However it appears that 3.3.4 is badly broken for voip, we had issues with Snom and Grandstream devices, a downgrade to 3.3.3 fixes everything!
I can see a few other people have had the same issue since we discovered this, so hopefully one of us will pop into google and save some head scratching 🙂
3.3.3 is still available for download on the draytek site – http://www.draytek.co.uk/support/download/v2820_333_232201_A.zip
Although a while back, been meaning to post this somewhere online. On a few servers we had a problem installing this update, the following worked a charm:
Under HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL.1\Setup\Resume, if set to 1, change to 0
Then install the update and reboot.
This issue started appearing since we upgraded to ESX4, and to be fair its happened maybe 3 times in total. ESX just disables the VM, stating in the logs:
The CPU has been disabled by the guest operating system
Jan 07 22:22:11.316: vcpu-0| The CPU has been disabled by the guest operating system. You will need to power off or reset the virtual machine at this point.
Some googling didnt turn up much, the machine wasn’t overcommited resource wise, and all other VM’s were fine, so off we go to open a support request with VMware. Short time later and they have identifed the following in the logs:
Jan 07 22:25:07.336: vmx| VMXVmdb_LoadRawConfig: Loading raw config Jan 07 22:25:07.415: vmx| Failed to extend memory file from 0x0 bytes -> 0x1000 bytes.
Jan 07 22:25:07.416: vmx| BusMem: Failed to allocate frames for region BusError.
Jan 07 22:25:07.417: vmx| Msg_Post: Error Jan 07 22:25:07.417: vmx| [msg.memVmnix.ftruncateFailed] Could not allocate 4096 bytes of anon memory: No space left on device.
Jan 07 22:25:07.418: vmx| [msg.moduletable.powerOnFailed] Module PhysMem power on failed.
Jan 07 22:25:07.419: vmx| —————————————-
Jan 07 22:25:07.590: vmx| VMX_PowerOn: ModuleTable_PowerOn = 0 Jan 07 22:25:08.618: vmx| Vix: [112100 mainDispatch.c:3248]: VMAutomation_ReportPowerOpFinished: statevar=1, newAppState=1873, success=1 Jan 07 22:25:08.618: vmx| Vix: [112100 mainDispatch.c:3254]: VMAutomation: Ignoring ReportPowerOpFinished because the VMX is shutting down.
Jan 07 22:25:08.619: vmx| Vix: [112100 mainDispatch.c:3248]: VMAutomation_ReportPowerOpFinished: statevar=0, newAppState=1870, success=1 Jan 07 22:25:08.620: vmx| Vix: [112100 mainDispatch.c:3254]: VMAutomation: Ignoring ReportPowerOpFinished because the VMX is shutting down.
Jan 07 22:25:08.825: vmx| Transitioned vmx/execState/val to poweredOff Jan 07 22:25:08.919: vmx| Vix: [112100 mainDispatch.c:3248]: VMAutomation_ReportPowerOpFinished: statevar=0, newAppState=1870, success=0 Jan 07 22:25:08.920: vmx| Vix: [112100 mainDispatch.c:3254]: VMAutomation: Ignoring ReportPowerOpFinished because the VMX is shutting down.
Jan 07 22:25:08.921: vmx| VMX idle exit
Jan 07 22:25:09.108: vmx| Vix: [112100 mainDispatch.c:599]: VMAutomation_LateShutdown() Jan 07 22:25:09.109: vmx| Vix: [112100 mainDispatch.c:549]: VMAutomationCloseListenerSocket. Closing listener socket.
Jan 07 22:25:09.466: vmx| Flushing VMX VMDB connections Jan 07 22:25:09.766: vmx| IPC_exit: disconnecting all threads Jan 07 22:25:09.766: vmx| VMX exit (0).
Jan 07 22:25:09.767: vmx| AIOMGR-S : stat o=280 r=427 w=6 i=255 br=6766592 bw=380928 Jan 07 22:25:09.768: vmx| VMX has left the building: 0.
While the resource management was trying to extend memory on the host for the VM it encountered an error. This triggered a failure and a automated power off of the vm. As I say nothing is overcommited and there are plenty of resources available on the host, the VM itself is not particularly intensive.
Some searching by VMware and it seems we have stumbled across a bug between them and our Equallogic arrays:
This is a known issue with Equalogic arrays (Problem Report No 484220) This issue will be fixed as part of ESX4 patch 5. The release date for this Patch is currently targeted for the the end of March. Looking through the PR, the only available workaround./suggestion to help reduce the occurrence of this issue is to ensure no vmknic binding and to have only 1 vmkernel port per vmnic.
So currently the only workaround is not to configure the vmnics/vmk ports as per Dell’s docs for multipathing on Equallogics! Hopefully this saves some searching 🙂